
Getting Data from LinkedIn Sucked, So I Made a Chrome Extension
GPT-4-Turbo with Vision has made it possible to gather and parse information in a new way from websites that have historically been gatekeepers


Quick update: I started making this tool a few weeks before GPT-4o came out. The biggest release in this update is screen recognition which is exactly what I was trying to solve for (rudimentally) with this Chrome extension. Taking action directly in the browser, especially as it relates to processing information directly on a webpage will be one of the biggest unlocks from OpenAI (or Google?) and it looks like they’re working towards just that.
Summary
GPT-4-Turbo with Vision is one of the most exciting things rolled out by the OpenAI team recently – the ability for LLMs to read images correctly will be an absolute game changer for just about every industry. One use case that stood out to me immediately is using this technology to gather information from sites that are incredibly hard to scrape – so I built a Chrome Extension (almost completely with the help of ChatGPT).
Let’s get into it.
Why now?
Let’s take a step back real quick to go over GPT-4-Turbo. The OpenAI team released the Turbo upgrade from 3.5 to 4 in November of last year. The big updates that had many excited were the increased context window (amount of text that model can consider when generating response – great primer here) and cheaper, improved performance from API responses. But in the third bullet of features from the DevDay announcement, OpenAI also casually announced “New multimodal capabilities in the platform, including vision, image creation (DALL·E 3), and text-to-speech (TTS)”.
The vision capabilities come from setting the Transformer architecture on visual data, but using a dual-stream architecture: Language and Vision Stream. The Language steam is similar to what we’ve seen in LLMs in the past – accepting and responding via textual data, but Vision Stream uses a Convolutional Neural Network to extract features like shapes, objects, and colors from an inputted image – another great primer here.
So why does this matter? Vision has been useful in creating output about pictures uploaded to the platform, but the immediate benefit that comes to my mind is the ability to use it against images that contain textual data that is in no state to be put into a JSON or CSV directly. More specifically, what if we use the GPT-4-Turbo API to feed these images in, prompt the model to return a schema that is database ingestion-ready? Let’s look at a real life example:
Take the latest Confluent 10-Q for example, say I want to turn the Cash Flow Statement into a JSON, with specified structure in order to get into whatever database I’m using, ChatGPT does a pretty good job of doing just that with a fair bit of prompting.
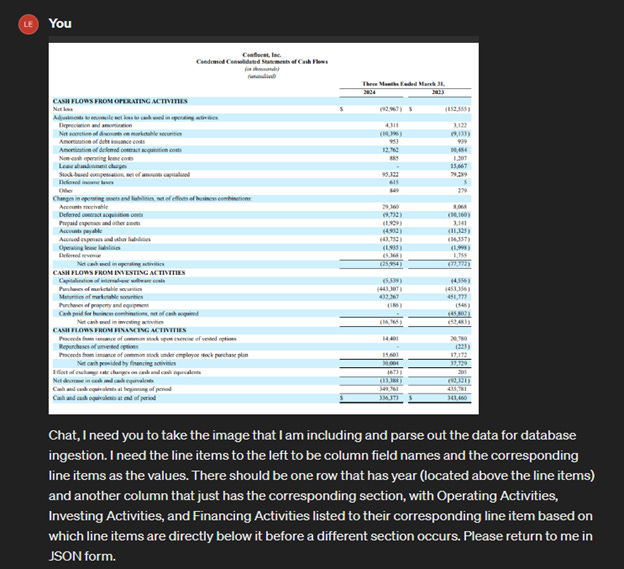

Accuracy leaves a little to be desired given hallucinating is still a real issue but the more you prompt the better it gets.
The issue here is that you’re still operating in the ChatGPT console which is a few extra steps when accounting for downloading and uploading elsewhere and in reality this stuff is provided via most financial aggregators like CapIQ or Factset. So lets take it a step further and bring it into a native Chrome Extension AND do something that is almost impossible to parse in a good way: LinkedIn people profiles.
Maybe my most important diatribe of this post is about the pain myself and thousands of others have gone through in trying to aggregate data from LinkedIn. If you’re in sales or just about any other tech-related role, you have, at some point needed LinkedIn data, whether on the company or person side. LinkedIn doesn’t sell this data (yet?) and makes it hell on earth to scrape, so we rely on 3rd party aggregators who take the raw HTML, parse out usable data, and sell it to us. But these providers are still littered with errors and bad data because LinkedIn 1) is superb at bot detection of crawlers entering the site (crawlers will need bells and whistles including proxy servers/rotating VPNs, mouse-simulator scripts, etc.); 2) these providers cannot pass in credentials to log-in and can only grab public information available to users when signed out, cutting down people-related datapoints by 90%+ (in my experience). One solution, as I will outline below is to not worry about trying to scrape the HTML but rather use GPT-Vision to grab exactly what you’re seeing on the page, parse it into a usable format and send it directly into your database.
Chrome Extension LinkedIn ‘Crawler’
Requirements:
To get this thing going, you’ll need a working OpenAI API Key and a cloud-hosted database (I’m using MongoDB Atlas). Full Page Screen Capture is not required but very helpful and the best way to capture full LinkedIn pages that I’ve seen. A more experienced dev could probably build the screenshot feature into this tool but I did not. One way or another, a user will need an image file of the LinkedIn page to be parsed.
Limitations:
Still working off of a PNG upload. This is directly on the Chrome Extension for ease of use in a single pane – it is incredibly hard to turn a webpage into a JPG/PNG programmatically via JavaScript so much easier to just use a bona fide existing chrome extension that does just this (and works scrolling LinkedIn). This also means you are unable “crawl” profiles in bulk from this Chrome Extension. Hallucinations are still a bit of an issue with the returned data but less and less over time. I expect this to be limited significantly with future models. Lastly, it is not cheap to call the Turbo API – looks to be about $0.10 on average per job. Again, I expect this to decrease significantly over time.
How it works
vision-chrome-extension contains the files necessary to load your own Chrome Extension for use in parsing the data on individual’s LinkedIn pages in (practically) real time. A user simply develops their prompt, outlining the schema of the JSON file they want returned along with some other basic rules or uses the current prompt already engineered to grab key information on a person’s LinkedIn page. Then, after feeding an image file taken with an existing chrome extension, the user will get back the formatted information, already largely parsed, returned directly in the chrome extension for inspection. The user can then push to a database directly on the extension. All sensitive information (API keys, database access information) is stored in the Chrome’s local storage for added security. This extension is not limited to LinkedIn but can be used for just about any image as long as the prompt is adapted. Included below are some links to the tool and other important resources as well as a demo of the product.
Conclusion
This is a tool that I hope will be obsolete soon. The steps it’s taking are incredibly simple and something I imagine (hope) will be baked into agents from all Foundational Model providers and beyond. That being said, I haven’t seen too much like it currently so I hope you find it useful.
Links:
Github Repo: https://github.com/lelandjfs/vision-chrome-extension
Chrome Extension Console: chrome://extensions/
MongoDB Realm SDK: https://www.npmjs.com/package/realm-web?activeTab=code
Screen Capture Chrome Extension: https://chromewebstore.google.com/detail/full-page-screen-capture/pmabjgjpcbofkbbeiphkiaanogobokgg?hl=en-US&utm_source=ext_sidebar
This is awesome. also more than slightly technical for non-tech people... feel like sales people would struggle to do this, even though it feels made for them.
why is linkedin so against scrapers? Just in case one day they want to monetize this data?